1. 问题描述
最近在工作中碰到安全组的同学,在编写一个用于加解密的 Filter时考虑问题不够周全导致的 bug。这个 Filter 的原意是在客户端根据一定的条件将请求的数据进行加密,同时在服务端对数据进行解密。于是,他写了一个 Filter 来过滤请求,部分代码如下所示:
1 |
|
将原始的请求包装成一个自定义的 HttpServletRequestWrapper,并重写了请求中获取参数的方法,以此来达到解密的目的:
1 | public class SecurityHttpServletRequestWrapper extends HttpServletRequestWrapper { |
自己定义了一个 Request Map,并对原始参数进行解密,同时覆盖一系列的 getXXX 方法,返回解密后的参数。应该说,在大部分情况下,这个设计是没错的,这也是安全 SDK 运行了好几个版本也没出什么问题的原因。
但是,我们如果去翻阅 HttpServletRequestWrapper 的源码会发现,这个类的方法数量远不止这么几个 getXXX,如下图所示:
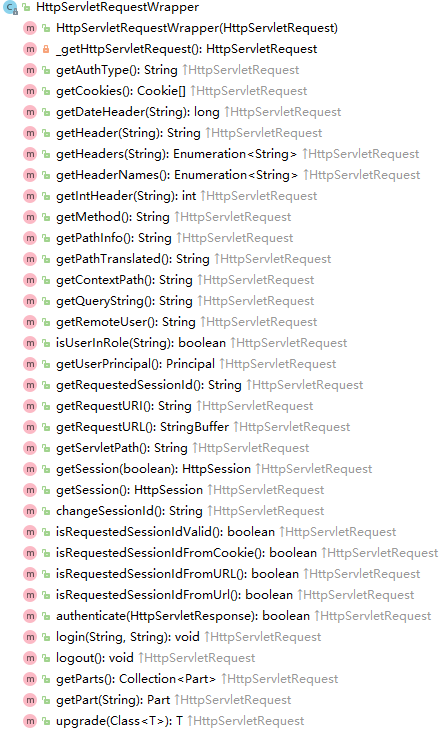
当然,并不是说这里所有的方法都需要去覆盖重写,但是与加解密安全相关的都必须要进行完整的覆盖,除了之前 SDK 中的 getXXX 之外,还至少应该覆盖如下的 API:
public int getContentLength()public long getContentLengthLong()public ServletInputStream getInputStream() throws IOException
其中:getContentLength() 以及 getContentLengthLong() 是因为加解密的过程势必会导致请求数据的大小发生变化,所以这里要重新计算并返回实际的数据长度。而 getInputStream() 则是因为有一些数据并不是通过 query 参数的方式进行传递的,比如我们今天要讨论的 @RequestBody。
所以当采用以上 SDK 时,对于常规的参数接入方式完全没有问题,如:
1 | (value = "vaid", notes = "获取 VAID") |
但是如果你尝试采用 @RequestBody 来接收参数,则会发生参数无法解析的问题:
1 | (value = "vaid", notes = "获取 VAID") |
因为 @RequestBody 的内容来自于 Request.getInputStream() ,而原 SDK 并没有对这部分数据进行处理。
2. SpringMVC 的参数处理流程
如果你用过 Spring2.x 及以下的版本,可能会比较清楚,通常我们在配置 SpringMVC 时,需要手动的给 HandlerAdapter 添加各种 HandlerMethodArgumentResolver,而这个 HandlerMethodArgumentResolver 就是用来处理各类参数转换及绑定的,由于太过久远,我们就不分析2.x版本的实现原理了。
2.1 RequestMappingHandlerMapping
我们看看从Spring3.x 之后提供的基于 Namespace 的配置方式(原理大同小异)。与 HandlerMethodArgumentResolver 相关的配置如下所示:
1 | <mvc:annotation-driven> |
它是包含在 \mvc:annotation-drive\ 中的,所以我们从源头分析起,这个 Namespace 的处理入口类是 MvcNamespaceHandler:
1 | public class MvcNamespaceHandler extends NamespaceHandlerSupport { |
这个节点是由 AnnotationDrivenBeanDefinitionParser 去解析的,在这个解析器里面非常重要的一点是定义了如下的 SpringBean——RequestMappingHandlerMapping:
1 |
|
这个 Bean 非常重要,是 SpringMVC 的几个核心之一,甚至说是 最 核心的也不为过。它定义了数据解析,参数绑定,返回值处理,视图解析,内容绑定,消息转换等等一系列的组件,所以这些组件的相互配合完成了所有 SpringMVC 的使命。
2.2 HandlerMethodArgumentResolver
上一节提到 RequestMappingHandlerMapping 是整个 SpringMVC 中最核心的组件,而其中整合了我们今天的主角:HandlerMethodArgumentResolver;这个组件主要有两个方法:
1 | /** |
这是设计模式中的 策略模式 的运用,整个 SpringMVC 中提供了许多的不同场景下的实现,在真正进行参数解析与绑定时,会遍历所有的 Resolver ,调用其 supportsParameter() 方法来确定是否支持当前这个参数的处理,如果支持,则再调用 resolveArgument() 方法来实现真正的参数解析(同时还会进行相应的绑定、转移过程,这利益于方法参数中的 WebDataBinderFactory 的支持)。
注:在 Spring 中,几乎所有的策略模式的实现都是类似这样的,先中收集所有的策略,然后supportsXXX() 方法来确定该策略是否符合当前的场景,最终在符合要求的策略上调用其 executeXXX() 之类的方法来完成真正的能力实现。
2.3 系统自带的 HandlerMethodArgumentResolver
了解了 HandlerMethodArgumentResolver 后我们再回到 RequestMappingHandlerMapping 组件中,看看 SpringMVC 自带了多少的 Resolver ,添加自带 Resolver 的过程在其 afterPropertiesSet() 方法,这个是 SpringBean 的生命周期回调方法(可以参考我另一篇文章《Spring中Bean的生命周期》),将在 Bean 构造完成后进行回调:
1 |
|
再看看这个获取自带 Resolver 的方法:
1 | /** |
可以看到共分为四类:
- Annotation-based argument resolution:基于注解处理的参数解析器
- Type-based argument resolution:基于类型的参数解析器
- Custom arguments resolution:用户自定义的解析器,我们在配置文件中添加的自定义解析器 就属于这类
- Catch-all:其它
这四个类型囊括了 SpringMVC 中所有的参数解析,使得我们在编写 Controller.method 时,不再需要手动的去 request 中去获取参数,绝大部分情况下只需要定义参数(或者注解参数)即可,而各个不同的 Resolver 会根据我们的定义(注解)完成对应的参数解析与绑定。
3. @RequestBody 的解析
了解了 SpringMVC 对于参数的解析过程后,我们再来看看第一章遇到的问题产生的原因及解决方案:@RequestBody 注解的参数是如何解析绑定定?
3.1 supportsParameter()
根据我们前面的分析,在四个参数解析器分类中,@RequestBody 的的解析应该是属于 基于注解处理的参数解析器 ,所以我们只需要在系统默认注册的那些基于注解处理的参数解析器中去查找分析即可。
同时,前面也提到,具体哪个 Resolver 会应用到这个参数的解析过程是由其 supportsParameter() 方法来决定的,那么就很容易的找到 RequestResponseBodyMethodProcessor 组件,我们看看它的源码部分:
1 | public class RequestResponseBodyMethodProcessor extends AbstractMessageConverterMethodProcessor { |
非常的简单,也很直接的通过 parameter.hasParameterAnnotation(RequestBody.class) 来声明该策略只处理标注有 @RequestBody 的参数;
3.2 resolveArgument()
真正解析参数的源码过程如下所示:
1 | public class RequestResponseBodyMethodProcessor extends AbstractMessageConverterMethodProcessor { |
注意:这里参数中的 InputMessage 实际就是 ServletServerHttpReques ,不要被名字给迷惑了
readWithMessageConverters 是最底层的参数解析及转移的过程,这个过程源码相对比较复杂,如下所示:
1 | /** |
抛开 Header 信息处理,分支处理,数据转换等,真正核心的数据都保存在 InputMessage.getBody(),而这个InputMessage 实际上就是 ServletServerHttpRequest,所以我们看看 ServletServerHttpRequest.getBody() 方法的源码如下:
1 |
|
这里分了两种场景:
通过表单提交:判定的依据是 content-type=”application/x-www-form-urlencoded”,同时 httpMethod=POST,这个时候,会将所有的表单序列化成字节流。如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33/**
* Use {@link javax.servlet.ServletRequest#getParameterMap()} to reconstruct the
* body of a form 'POST' providing a predictable outcome as opposed to reading
* from the body, which can fail if any other code has used the ServletRequest
* to access a parameter, thus causing the input stream to be "consumed".
*/
private static InputStream getBodyFromServletRequestParameters(HttpServletRequest request) throws IOException {
ByteArrayOutputStream bos = new ByteArrayOutputStream(1024);
Writer writer = new OutputStreamWriter(bos, FORM_CHARSET);
Map<String, String[]> form = request.getParameterMap();
for (Iterator<String> nameIterator = form.keySet().iterator(); nameIterator.hasNext();) {
String name = nameIterator.next();
List<String> values = Arrays.asList(form.get(name));
for (Iterator<String> valueIterator = values.iterator(); valueIterator.hasNext();) {
String value = valueIterator.next();
writer.write(URLEncoder.encode(name, FORM_CHARSET));
if (value != null) {
writer.write('=');
writer.write(URLEncoder.encode(value, FORM_CHARSET));
if (valueIterator.hasNext()) {
writer.write('&');
}
}
}
if (nameIterator.hasNext()) {
writer.append('&');
}
}
writer.flush();
return new ByteArrayInputStream(bos.toByteArray());
}
- 通过 body 提交:直接返回 ServletRequest.getInputStream() 即可
4. 总结
根据以上的分析,我们很清楚的知道了第一节中提到的 BUG 的问题根源所在:@RequestBody 参数的绑定是由 RequestResponseBodyMethodProcessor 完成的,而 RequestResponseBodyMethodProcessor 在进行 resolveArgument 时会通过 ServletRequest.getInputStream() 读取数据流,从而完成最终的数据转换、绑定。而安全 SDK 并没有对 ServletRequest.getInputStream() 进行任何的支持,从而导致读取的数据(加密后)不符合 application/json 的格式规范,进而抛出异常。
知道原因后解决的方案就比较清晰了,就是在加解密的时候对于 ServletRequest.getInputStream() 数据同样要进行相应的处理。
当然,更严谨的来说,前面提到的 getContentLength(),getContentLengthLong() 最好也要进行处理,虽然这里并没有涉及到这两个方法的执行。但 对于一些网络相关的优化或者压缩支持的时候,这两个方法是非常重要的,当实际的数据长度和这两个方法返回的数据不一致,会导致一些丢包或者数据展示不全的 bug 。
5. 后记
现在 Spring/SpringBoot 的更新迭代与优化后,框架的自动化程度越来越高,编写 Spring 相关的应用会越来越简单,提高了开发的生产效率。
但是,另一方面,过多的自动化,过多的细节隐藏导致的后果是越来越多的人不知道背后的原理,一旦出现问题时手足无措,不知道从哪里开始分析与排查。
所以,这里建议,想要真正学好用好 Spring 框架,可以尝试使用 Spring1.x/2.x 的版本去写一些测试 demo 应用。这两个版本的 Spring 配置过程比较复杂,各个组件都需要自己去配置,关联关系都需要自己去维护,但正因为如此,开发者更能够理解各个组件的功能、之间的依赖关系,更能够从底层的去了解 Spring 的运行原理。

